
save 메서드 동작 원리
save 메서드는 DB에 존재하는 엔티티라면 persist 메서드를 호출하고, 존재하지 않는 데이터라면 merge 메서드를 호출합니다.
public <S extends T> S save(S entity) {
Assert.notNull(entity, "Entity must not be null.");
if (entityInformation.isNew(entity)) {
em.persist(entity);
return entity;
} else {
return em.merge(entity);
}
}org.springframework.data.jpa.repository.support.SimpleJpaRepository<T,ID>
isNew 메서드는 save 메서드를 호출하시는 시점에 엔티티의 ID 값의 null 여부로 존재하는 데이터인지 아닌지를 판단합니다.
public boolean isNew(T entity) {
ID id = getId(entity);
Class<ID> idType = getIdType();
if (!idType.isPrimitive()) {
return id == null;
}
…
}org.springframework.data.repository.core.support.AbstractEntityInformation<T,ID>
merge 메서드를 호출하면 영속 컨텍스트의 1차 캐시에 엔티티가 존재하는 지 찾고, 존재하지 않으면 DB를 조회합니다. 병합 시 저장하려는 엔티티와 1차 캐시의 엔티티가 다를 경우 UPDATE 쿼리를 호출하기 위해 사용됩니다.
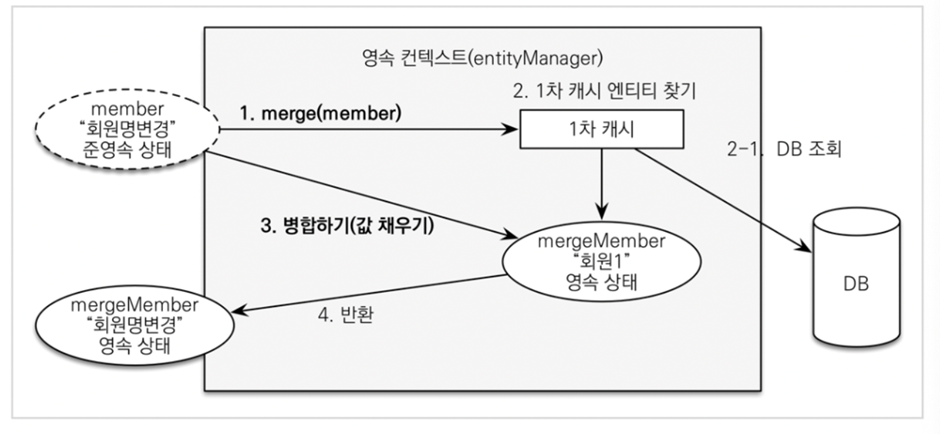
즉, save 메서드로 저장하려는 엔티티의 ID 값이 존재하고, 영속 컨텍스트의 1차 캐시에 엔티티가 존재하지 않을 경우 DB 조회를 합니다.
PK 생성 전략
저장하려는 엔티티의 ID 값의 존재 유무에 따라 persist 또는 merge 메서드를 호출할지 결정이 되며 merge 메서드를 호출하면 DB 조회를 할 수 있다는 것을 알게 됐습니다. 변경하려는 엔티티는 항상 ID 값이 존재하므로 merge 메서드를 호출하지만, 등록하려는 엔티티는 PK 생성 전략에 따라 ID 값이 존재 유무가 다릅니다.
자동 생성 - IDENTITY
@Id
@Column(name = "srnm")
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;기본 키 생성을 데이터베이스에 위임하는 전략입니다. MySQL 에서는 AUTO INCREMENT 설정을 합니다. 자동으로 DB에서 ID 값을 생성해주기 때문에 엔티티를 등록할 때 엔티티의 ID 값은 비어 있는 상태입니다. 따라서 매번 persist 메서드를 호출하므로 DB 조회를 하지 않습니다.
직접 할당
@EmbeddedId
@Column(name = "order_no")
private OrderId orderId;기본 키를 애플리케이션에서 직접 할당하는 전략입니다. 엔티티를 DB에 저장할 때 ID 값을 애플리케이션에서 직접 할당하므로 매번 merge 메서드를 호출합니다. 영속 컨텍스트의 1차 캐시에 엔티티가 존재하지 않는다면, DB 조회를 합니다.
성능 이슈
직접 할당의 경우 엔티티를 저장할 때 매번 ID값이 존재하므로 신규로 엔티티를 등록하고 싶은 경우에도 merge 메서드를 호출합니다. 따라서 신규 등록 시 save 메서드를 호출하기 전에 DB 조회를 합니다.
이 문제를 해결하기 위해 엔티티를 등록할지 변경할지 판단하는 Persistable 인터페이스의 isNew 메서드를 오버라이딩합니다. 엔티티의 ID 값의 유무로 판단하는 것이 아닌, 등록 시간(예시)의 유무로 판단을 하게 해줌으로써 등록 시간이 존재하지 않는 엔티티는 persist 메서드를 호출하므로 DB 조회를 하지 않습니다.
public class OrderInfo implements Persistable<OrderId> {
@EmbeddedId
@Column(name = "order_no")
private OrderId orderId;
@Column(name = "reg_dtm", updatable = false)
@CreatedDate
private LocalDateTime regDate;
@Override
public CustomerId getId() {
return this.orderId;
}
@Override
public boolean isNew() {
return this.regDate == null;
}
}
테이블 성격 별 저장 방법
변경 가능한 테이블
AUTO INCREMENT 사용 시
PK 가 자동 생성되므로 IDENTITY 전략을 사용하면 됩니다.
등록 시에는 PK 값이 null 이므로 JPA는 신규 데이터라고 판별하고 항상 persist 메서드를 호출합니다.
변경 시에는 조회 -> 엔티티 필드 값 수정 -> save 메서드 호출 순서로 로직을 실행하므로 PK 값이 항상 존재합니다.
그러므로 merge 메서드를 호출할 것이고, 조회 시 영속성 컨텍스트의 1차 캐시에 엔티티를 저장하므로 추가적인 DB 조회는 하지 않습니다.
AUTO INCREMENT 미사용 시
PK 가 자동 생성되지 않으므로 직접할당을 해줍니다. 그리고 성능 이슈를 해결하기 위해 해당 엔티티에서 Persistable 인터페이스를 구현합니다. 이 경우 신규 데이터인지 아닌지를 오버라이딩한 isNew 메서드로 판별합니다.
isNew 메서드가 true이면 persist 메서드를 호출합니다. Persist 메서드 호출 시 DB 조회를 하지 않고 insert 문을 실행합니다.
isNew 메서드가 false이면 merge 메서드를 호출합니다. Merge 메서드 호출 시 영속성 컨텍스트의 1차 캐시에 데이터가 존재하면 update 문만 실행하고, 존재하지 않으면 select 문을 실행 후 update 문을 실행합니다.
이력 테이블
이력 테이블의 경우 등록하고 변경하지는 않습니다.
데이터를 순서대로 DB에 쌓으면 되기 때문에 PK 생성 전략을 IDENTITY 로 사용하면 됩니다.
save 메서드를 호출할 때 항상 PK 값이 null 이므로 JPA는 신규 데이터라고 판별하고 항상 persist 메서드를 호출합니다.
참고 자료
- https://velog.io/@skyepodium/JPA-%EA%B8%B0%EB%B3%B8%ED%82%A4-%EB%A7%A4%ED%95%91-%EC%A0%84%EB%9E%B5
'Spring' 카테고리의 다른 글
| MapStruct (0) | 2023.11.28 |
|---|---|
| Save, SaveAndFlush 차이 (0) | 2023.11.28 |
| Valid 어노테이션 커스텀해서 사용하기 (0) | 2023.10.22 |
| Valid, Validated 어노테이션 (0) | 2023.09.24 |
| 조회 쿼리 메서드 사용 시 불필요한 Join 이 사용되는 이유 (0) | 2023.09.14 |