
Clustered Index
Clustered Index는 row의 물리적 정렬 순서를 설정하는 index입니다. PK를 설정하면
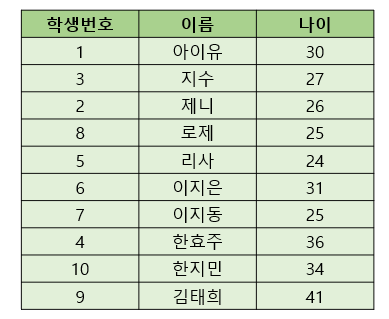
위와 같이 clustered Index가 없이 정렬되지 않은 테이블이 있습니다.
이 테이블은 내부적으로 아래와 같이 Data Page 단위로 저장됩니다.
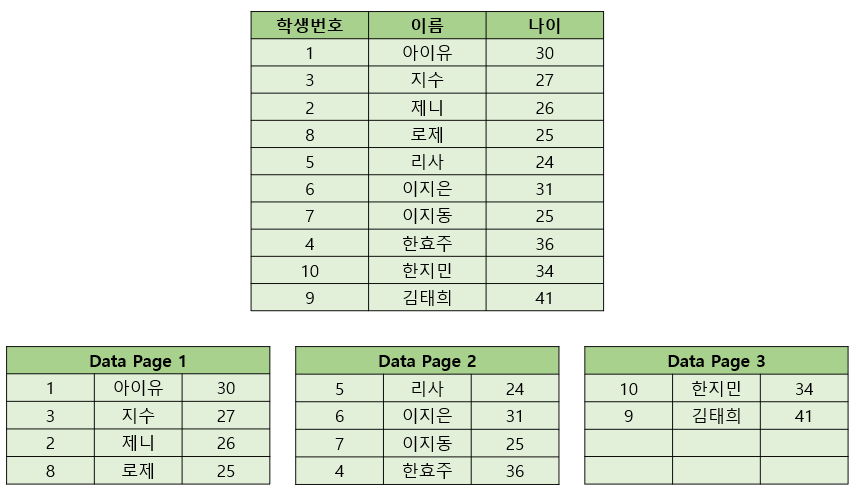
이때 학생 번호 6에 해당하는 학생 데이터를 조회하려 합니다. 데이터가 정렬되어 있지 않기 때문에 어떤 Data Page에 6번 학생이 존재하는지 모릅니다. 따라서 모든 Data Page를 순서대로 조회합니다.
최악의 경우 마지막에 존재하는 데이터를 찾기 위해 모든 Data Page의 학생 데이터를 탐색하게 됩니다.
이를 테이블 스캔이라고 합니다.

Clustered Index 생성
위의 그림에서 학생번호를 PK로 설정하면 자동으로 Clustered Index를 생성하고 다음과 같은 순서로 작업이 진행됩니다.
1. 기존 Data Page의 데이터들이 PK인 '학생번호를 기준으로 정렬되어 새로운 Data Page 에 저장됩니다.
(1, 2, 3 -> 4, 5, 6)
2. Index Page가 생성되고, 각각의 Data Page 의 첫 번째 PK 값과 Data Page 번호를 저장합니다.
3. 기존의 Data Page는 제거됩니다.
이때 Index Page를 Root Page, Data Page 를 Leaf Page라고 부릅니다.
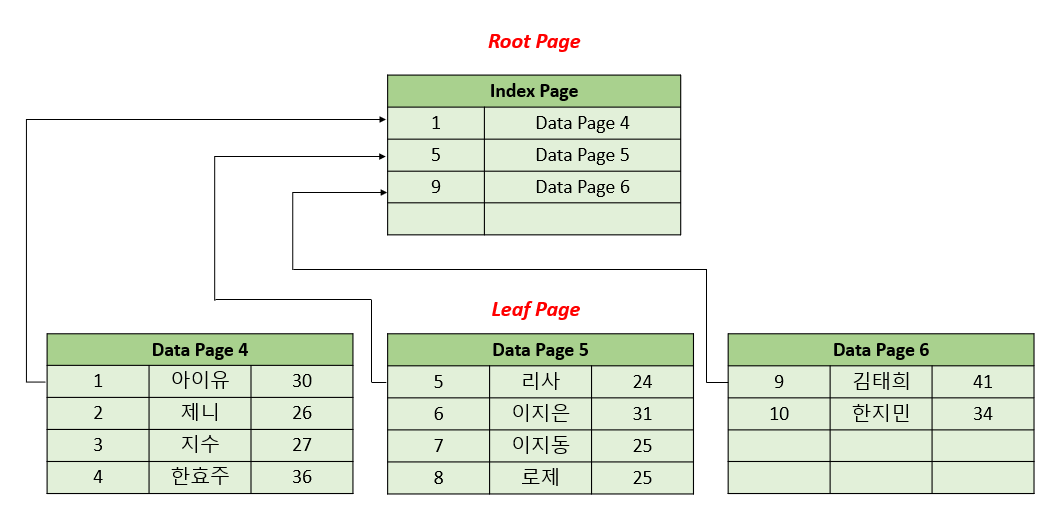
Clustered Index 생성 후 조회 시
PK를 설정 후 학생 번호 6으로 데이터를 조회하려 합니다.
1. Index Page 에서 학생 번호 6에 해당하는 Date Page를 찾습니다. (6은 5와 9 사이의 숫자이므로 Data Page 5에 존재한다고 판단)
2. Data Page 에서 학생 번호 6에 해당하는 학생 데이터를 찾습니다.
이러한 탐색을 인덱스 스캔이라고 합니다.
인덱스 스캔은 특정 Leaf Page 만 탐색하므로 전체 Data Page를 탐색하는 테이블 스캔보다 훨씬 빠릅니다.

Non-Clustered Index
Clustered Index 컬럼으로 조회할 수도 있지만 다른 컬럼으로 조회를 할 수도 있습니다.
예를 들어 학생 이름으로 조회를 한다면, 인덱스화된 Data Page 를 처음부터 끝까지 탐색하며 데이터를 찾습니다.
이를 전체 인덱스 스캔이라고 합니다.

그러면 학생 이름 컬럼도 'Clustered Index로 설정하자!'라고 생각할 수 있지만, Clustered Index는 테이블 당 하나만 설정 가능합니다.
이러한 문제를 해결할 수 있는게 Non-Clustered Index입니다.
다음은 학생 이름을 Non-Clustered Index로 설정한 그림입니다.
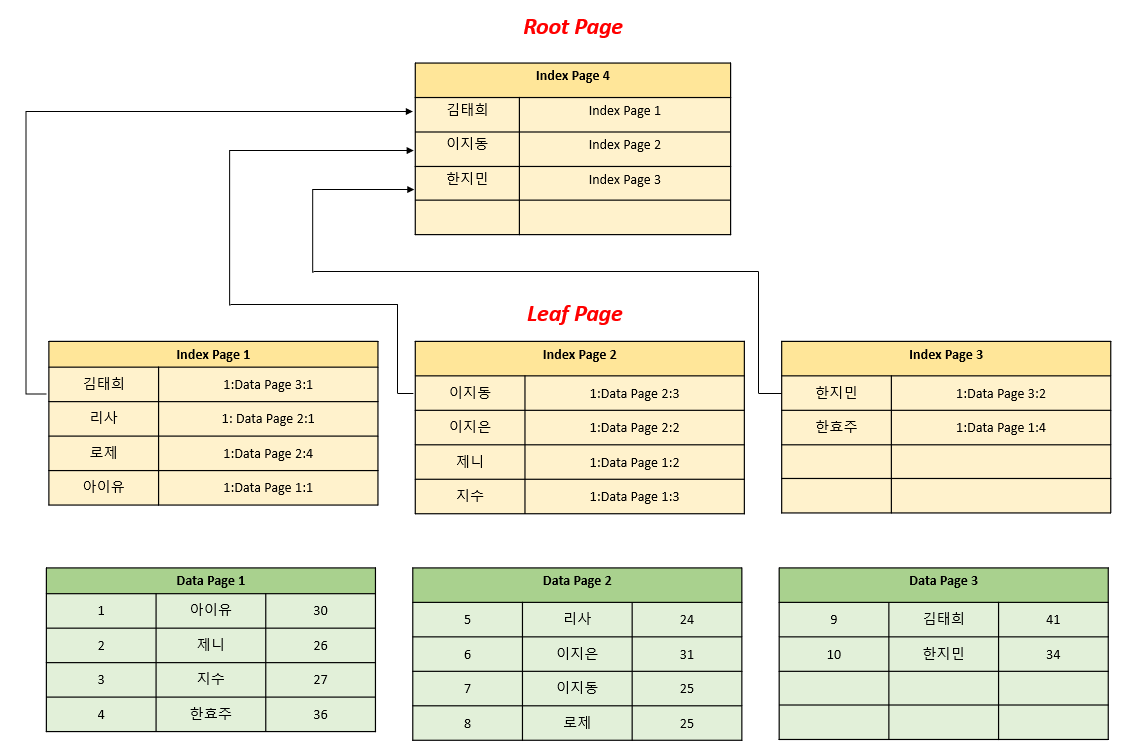
Non-Clustered Index 생성
기존의 PK 설정 시 생성된 Data Page는 그대로 존재합니다. 대신 신규 Index Page들을 생성합니다.
Index Page 1, 2, 3은 인덱스(이름)와 RID(Row Identifier) [파일 : Data Page : Row]를 가집니다.
이러한 Index Page를 Leaf Page라고 합니다.
Index Page 4는 Leaf Page의 첫 번째 값과 인덱스 페이지 번호를 저장합니다.
이러한 Index Page를 Root Page라고 합니다.
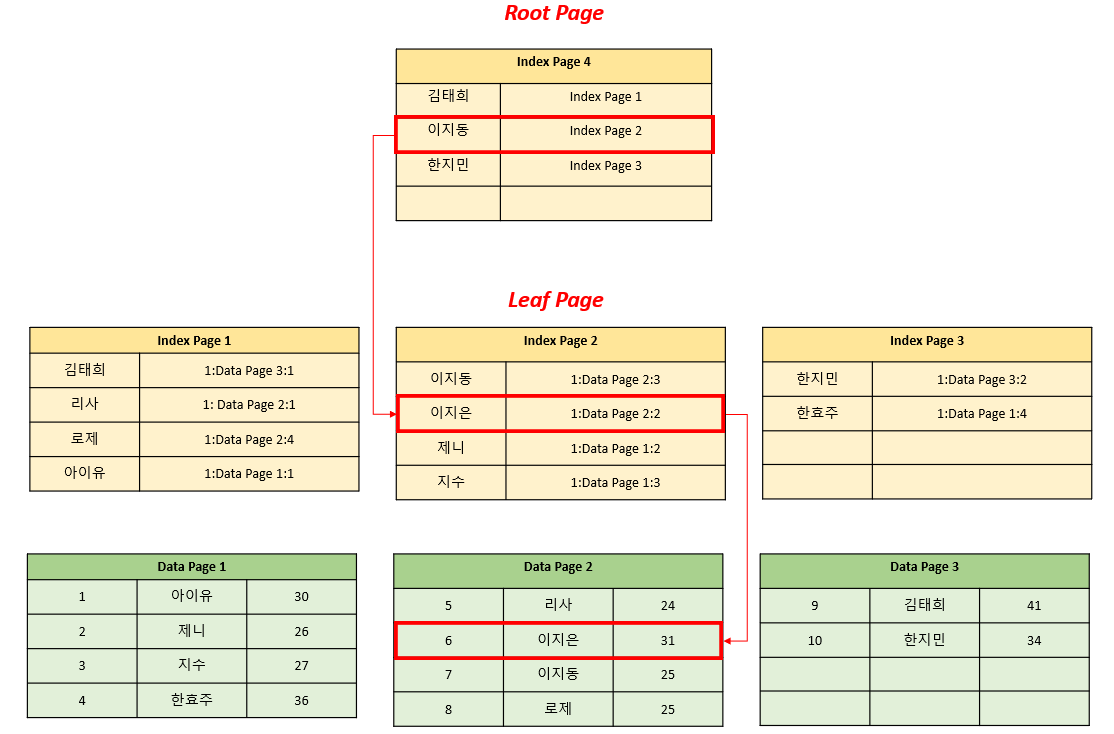
Non-Clustered Index 생성 후 조회 시
학생 테이블에서 '이지은' 이름으로 데이터를 조회한다고 가정하면,
1. Root Page에서 이름에 해당하는 Leaf Page를 탐색합니다. (이지동과 한지민 사이에 존재하므로 Index Page 2에 존재할 것입니다.)
2. Leaf Page에서 이름에 해당하는 RID를 탐색합니다. (Data Page 2의 2번째 값)
3. Data Page에서 RID에 해당하는 데이터를 반환합니다.
1번 과정을 Index Seek, 2번 과정을 RID Lookup이라고 합니다.
Non-Clustered Index는 한 테이블 당 여러 개를 생성할 수 있습니다.
그러나 인덱스 페이지를 위한 별도의 공간이 필요합니다.
참고 자료
https://code-lab1.tistory.com/280
[DB] Clustered Index 와 Non-Clustered Index 차이 | 테이블 스캔(Table Scan)이란? 인덱스 스캔(Index Scan)이란?
Index란? Index는 테이블에서 데이터의 위치를 가리키는 자료구조이다. Index가 없다면 원하는 데이터를 찾기 위해서 테이블 전체를 뒤져야 할 것이다. 이러한 Index는 크게 Clustered Index와 Non-Clustered In
code-lab1.tistory.com
'Database' 카테고리의 다른 글
| MySQL 실행계획 (1) | 2023.10.15 |
|---|---|
| Mysql 아키텍처 (0) | 2023.10.15 |
| Unknown system variable 'transaction_isolation' (0) | 2023.09.14 |
| B-Tree 인덱스 (0) | 2023.09.14 |
| NoSQL (0) | 2023.09.14 |